Build a Retrieval Augmented Generation (RAG) App
One of the most powerful applications enabled by LLMs is sophisticated question-answering (Q&A) chatbots. These are applications that can answer questions about specific source information. These applications use a technique known as Retrieval Augmented Generation, or RAG.
This tutorial will show how to build a simple Q&A application over a text data source. Along the way we’ll go over a typical Q&A architecture and highlight additional resources for more advanced Q&A techniques. We’ll also see how LangSmith can help us trace and understand our application. LangSmith will become increasingly helpful as our application grows in complexity.
If you’re already familiar with basic retrieval, you might also be interested in this high-level overview of different retrieval techinques.
What is RAG?
RAG is a technique for augmenting LLM knowledge with additional data.
LLMs can reason about wide-ranging topics, but their knowledge is limited to the public data up to a specific point in time that they were trained on. If you want to build AI applications that can reason about private data or data introduced after a model’s cutoff date, you need to augment the knowledge of the model with the specific information it needs. The process of bringing the appropriate information and inserting it into the model prompt is known as Retrieval Augmented Generation (RAG).
LangChain has a number of components designed to help build Q&A applications, and RAG applications more generally.
Note: Here we focus on Q&A for unstructured data. If you are interested for RAG over structured data, check out our tutorial on doing question/answering over SQL data.
Concepts
A typical RAG application has two main components:
Indexing: a pipeline for ingesting data from a source and indexing it. This usually happens offline.
Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
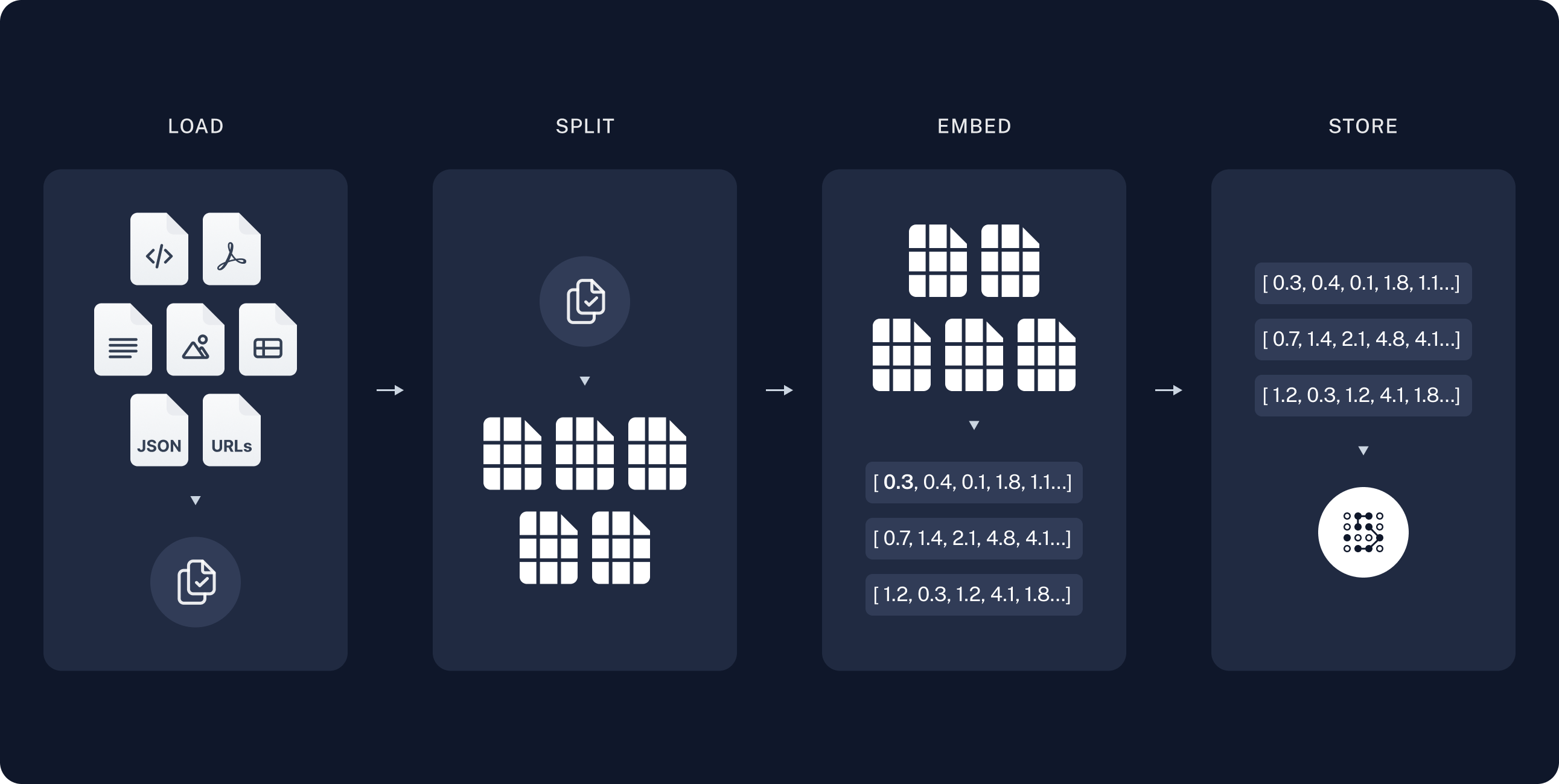
The most common full sequence from raw data to answer looks like:
Indexing
- Load: First we need to load our data. This is done with Document Loaders.
- Split: Text splitters break
large
Documentsinto smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won’t fit in a model’s finite context window. - Store: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.
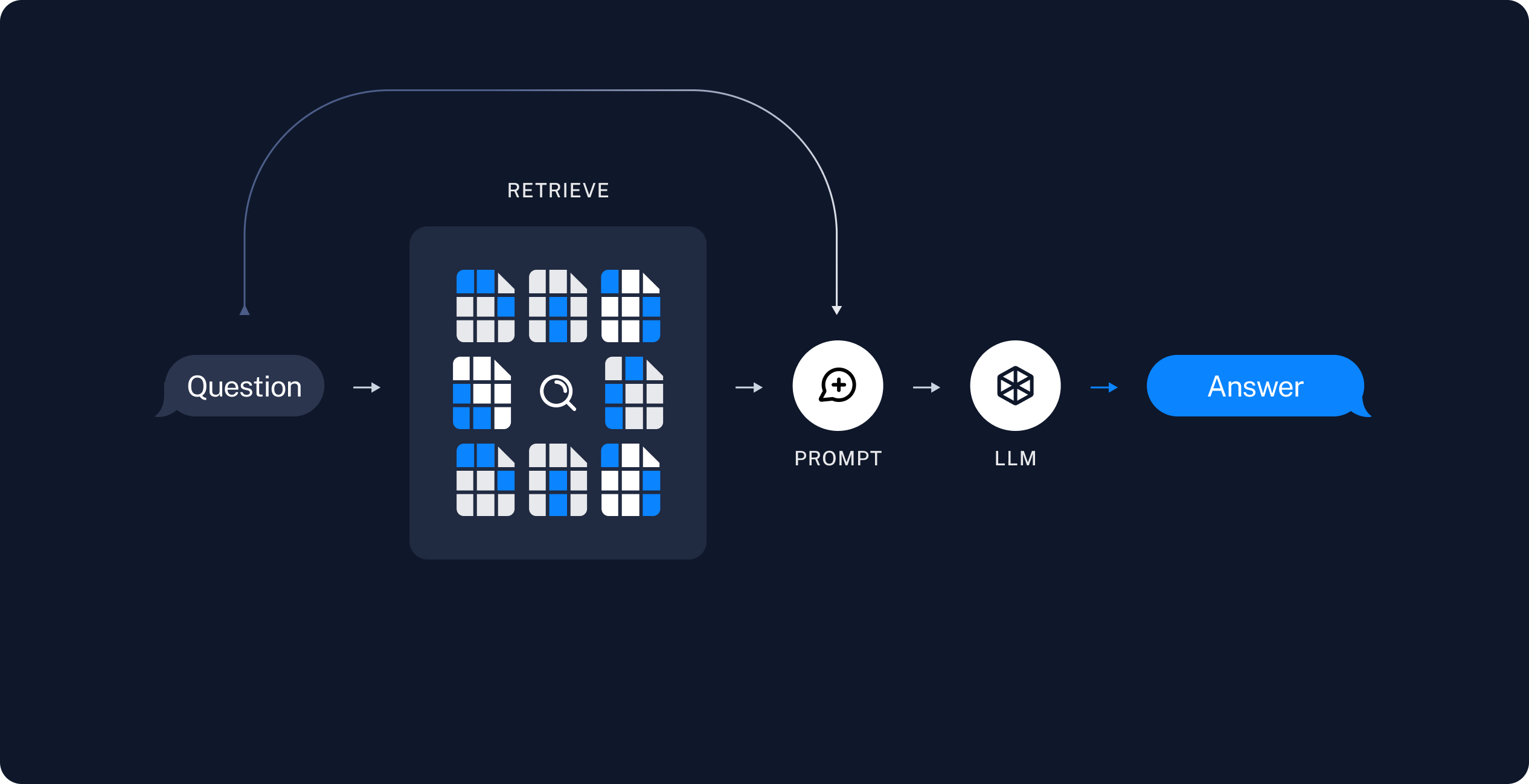
Retrieval and generation
- Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
- Generate: A ChatModel / LLM produces an answer using a prompt that includes the question and the retrieved data
Setup
Installation
To install LangChain run:
bash npm2yarn npm i langchain
For more details, see our Installation guide.
LangSmith
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more and more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.
After you sign up at the link above, make sure to set your environment variables to start logging traces:
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."
Pick your chat model:
- OpenAI
- Anthropic
- FireworksAI
- MistralAI
- Groq
- VertexAI
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
Add environment variables
OPENAI_API_KEY=your-api-key
Instantiate the model
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/anthropic
yarn add @langchain/anthropic
pnpm add @langchain/anthropic
Add environment variables
ANTHROPIC_API_KEY=your-api-key
Instantiate the model
import { ChatAnthropic } from "@langchain/anthropic";
const llm = new ChatAnthropic({
model: "claude-3-5-sonnet-20240620",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
Add environment variables
FIREWORKS_API_KEY=your-api-key
Instantiate the model
import { ChatFireworks } from "@langchain/community/chat_models/fireworks";
const llm = new ChatFireworks({
model: "accounts/fireworks/models/llama-v3p1-70b-instruct",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
Add environment variables
MISTRAL_API_KEY=your-api-key
Instantiate the model
import { ChatMistralAI } from "@langchain/mistralai";
const llm = new ChatMistralAI({
model: "mistral-large-latest",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/groq
yarn add @langchain/groq
pnpm add @langchain/groq
Add environment variables
GROQ_API_KEY=your-api-key
Instantiate the model
import { ChatGroq } from "@langchain/groq";
const llm = new ChatGroq({
model: "mixtral-8x7b-32768",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
Add environment variables
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
Instantiate the model
import { ChatVertexAI } from "@langchain/google-vertexai";
const llm = new ChatVertexAI({
model: "gemini-1.5-flash",
temperature: 0
});
Preview
In this guide we’ll build a QA app over the LLM Powered Autonomous Agents blog post by Lilian Weng, which allows us to ask questions about the contents of the post.
We can create a simple indexing pipeline and RAG chain to do this in only a few lines of code:
import "cheerio";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings, ChatOpenAI } from "@langchain/openai";
import { pull } from "langchain/hub";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { createStuffDocumentsChain } from "langchain/chains/combine_documents";
const loader = new CheerioWebBaseLoader(
"https://lilianweng.github.io/posts/2023-06-23-agent/"
);
const docs = await loader.load();
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const splits = await textSplitter.splitDocuments(docs);
const vectorStore = await MemoryVectorStore.fromDocuments(
splits,
new OpenAIEmbeddings()
);
// Retrieve and generate using the relevant snippets of the blog.
const retriever = vectorStore.asRetriever();
const prompt = await pull<ChatPromptTemplate>("rlm/rag-prompt");
const llm = new ChatOpenAI({ model: "gpt-3.5-turbo", temperature: 0 });
const ragChain = await createStuffDocumentsChain({
llm,
prompt,
outputParser: new StringOutputParser(),
});
const retrievedDocs = await retriever.invoke("what is task decomposition");
Let’s see what this prompt actually looks like:
console.log(prompt.promptMessages.map((msg) => msg.prompt.template).join("\n"));
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
await ragChain.invoke({
question: "What is task decomposition?",
context: retrievedDocs,
});
"Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. I"... 259 more characters
Checkout this LangSmith trace of the chain above.
You can also construct the RAG chain above in a more declarative way
using a RunnableSequence. createStuffDocumentsChain is basically a
wrapper around RunnableSequence, so for more complex chains and
customizability, you can use RunnableSequence directly.
import { formatDocumentsAsString } from "langchain/util/document";
import {
RunnableSequence,
RunnablePassthrough,
} from "@langchain/core/runnables";
const declarativeRagChain = RunnableSequence.from([
{
context: retriever.pipe(formatDocumentsAsString),
question: new RunnablePassthrough(),
},
prompt,
llm,
new StringOutputParser(),
]);
await declarativeRagChain.invoke("What is task decomposition?");
"Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. I"... 208 more characters
LangSmith trace.
Detailed walkthrough
Let’s go through the above code step-by-step to really understand what’s going on.
1. Indexing: Load
We need to first load the blog post contents. We can use
DocumentLoaders for this, which are
objects that load in data from a source and return a list of
Documents.
A Document is an object with some pageContent (string) and metadata
(Record<string, any>).
In this case we’ll use the CheerioWebBaseLoader, which uses cheerio to load HTML form web URLs and parse it to text. We can pass custom selectors to the constructor to only parse specific elements:
const pTagSelector = "p";
const loader = new CheerioWebBaseLoader(
"https://lilianweng.github.io/posts/2023-06-23-agent/",
{
selector: pTagSelector,
}
);
const docs = await loader.load();
console.log(docs[0].pageContent.length);
22054
console.log(docs[0].pageContent);
Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:A complicated task usually involves many steps. An agent needs to know what they are and plan ahead.Chain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.Self-reflection is a vital aspect that allows autonomous agents to improve iteratively by refining past action decisions and correcting previous mistakes. It plays a crucial role in real-world tasks where trial and error are inevitable.ReAct (Yao et al. 2023) integrates reasoning and acting within LLM by extending the action space to be a combination of task-specific discrete actions and the language space. The former enables LLM to interact with the environment (e.g. use Wikipedia search API), while the latter prompting LLM to generate reasoning traces in natural language.The ReAct prompt template incorporates explicit steps for LLM to think, roughly formatted as:In both experiments on knowledge-intensive tasks and decision-making tasks, ReAct works better than the Act-only baseline where Thought: … step is removed.Reflexion (Shinn & Labash 2023) is a framework to equips agents with dynamic memory and self-reflection capabilities to improve reasoning skills. Reflexion has a standard RL setup, in which the reward model provides a simple binary reward and the action space follows the setup in ReAct where the task-specific action space is augmented with language to enable complex reasoning steps. After each action $a_t$, the agent computes a heuristic $h_t$ and optionally may decide to reset the environment to start a new trial depending on the self-reflection results.The heuristic function determines when the trajectory is inefficient or contains hallucination and should be stopped. Inefficient planning refers to trajectories that take too long without success. Hallucination is defined as encountering a sequence of consecutive identical actions that lead to the same observation in the environment.Self-reflection is created by showing two-shot examples to LLM and each example is a pair of (failed trajectory, ideal reflection for guiding future changes in the plan). Then reflections are added into the agent’s working memory, up to three, to be used as context for querying LLM.Chain of Hindsight (CoH; Liu et al. 2023) encourages the model to improve on its own outputs by explicitly presenting it with a sequence of past outputs, each annotated with feedback. Human feedback data is a collection of $D_h = \{(x, y_i , r_i , z_i)\}_{i=1}^n$, where $x$ is the prompt, each $y_i$ is a model completion, $r_i$ is the human rating of $y_i$, and $z_i$ is the corresponding human-provided hindsight feedback. Assume the feedback tuples are ranked by reward, $r_n \geq r_{n-1} \geq \dots \geq r_1$ The process is supervised fine-tuning where the data is a sequence in the form of $\tau_h = (x, z_i, y_i, z_j, y_j, \dots, z_n, y_n)$, where $\leq i \leq j \leq n$. The model is finetuned to only predict $y_n$ where conditioned on the sequence prefix, such that the model can self-reflect to produce better output based on the feedback sequence. The model can optionally receive multiple rounds of instructions with human annotators at test time.To avoid overfitting, CoH adds a regularization term to maximize the log-likelihood of the pre-training dataset. To avoid shortcutting and copying (because there are many common words in feedback sequences), they randomly mask 0% - 5% of past tokens during training.The training dataset in their experiments is a combination of WebGPT comparisons, summarization from human feedback and human preference dataset.The idea of CoH is to present a history of sequentially improved outputs in context and train the model to take on the trend to produce better outputs. Algorithm Distillation (AD; Laskin et al. 2023) applies the same idea to cross-episode trajectories in reinforcement learning tasks, where an algorithm is encapsulated in a long history-conditioned policy. Considering that an agent interacts with the environment many times and in each episode the agent gets a little better, AD concatenates this learning history and feeds that into the model. Hence we should expect the next predicted action to lead to better performance than previous trials. The goal is to learn the process of RL instead of training a task-specific policy itself.The paper hypothesizes that any algorithm that generates a set of learning histories can be distilled into a neural network by performing behavioral cloning over actions. The history data is generated by a set of source policies, each trained for a specific task. At the training stage, during each RL run, a random task is sampled and a subsequence of multi-episode history is used for training, such that the learned policy is task-agnostic.In reality, the model has limited context window length, so episodes should be short enough to construct multi-episode history. Multi-episodic contexts of 2-4 episodes are necessary to learn a near-optimal in-context RL algorithm. The emergence of in-context RL requires long enough context.In comparison with three baselines, including ED (expert distillation, behavior cloning with expert trajectories instead of learning history), source policy (used for generating trajectories for distillation by UCB), RL^2 (Duan et al. 2017; used as upper bound since it needs online RL), AD demonstrates in-context RL with performance getting close to RL^2 despite only using offline RL and learns much faster than other baselines. When conditioned on partial training history of the source policy, AD also improves much faster than ED baseline.(Big thank you to ChatGPT for helping me draft this section. I’ve learned a lot about the human brain and data structure for fast MIPS in my conversations with ChatGPT.)Memory can be defined as the processes used to acquire, store, retain, and later retrieve information. There are several types of memory in human brains.Sensory Memory: This is the earliest stage of memory, providing the ability to retain impressions of sensory information (visual, auditory, etc) after the original stimuli have ended. Sensory memory typically only lasts for up to a few seconds. Subcategories include iconic memory (visual), echoic memory (auditory), and haptic memory (touch).Short-Term Memory (STM) or Working Memory: It stores information that we are currently aware of and needed to carry out complex cognitive tasks such as learning and reasoning. Short-term memory is believed to have the capacity of about 7 items (Miller 1956) and lasts for 20-30 seconds.Long-Term Memory (LTM): Long-term memory can store information for a remarkably long time, ranging from a few days to decades, with an essentially unlimited storage capacity. There are two subtypes of LTM:We can roughly consider the following mappings:The external memory can alleviate the restriction of finite attention span. A standard practice is to save the embedding representation of information into a vector store database that can support fast maximum inner-product search (MIPS). To optimize the retrieval speed, the common choice is the approximate nearest neighbors (ANN) algorithm to return approximately top k nearest neighbors to trade off a little accuracy lost for a huge speedup.A couple common choices of ANN algorithms for fast MIPS:Check more MIPS algorithms and performance comparison in ann-benchmarks.com.Tool use is a remarkable and distinguishing characteristic of human beings. We create, modify and utilize external objects to do things that go beyond our physical and cognitive limits. Equipping LLMs with external tools can significantly extend the model capabilities.MRKL (Karpas et al. 2022), short for “Modular Reasoning, Knowledge and Language”, is a neuro-symbolic architecture for autonomous agents. A MRKL system is proposed to contain a collection of “expert” modules and the general-purpose LLM works as a router to route inquiries to the best suitable expert module. These modules can be neural (e.g. deep learning models) or symbolic (e.g. math calculator, currency converter, weather API).They did an experiment on fine-tuning LLM to call a calculator, using arithmetic as a test case. Their experiments showed that it was harder to solve verbal math problems than explicitly stated math problems because LLMs (7B Jurassic1-large model) failed to extract the right arguments for the basic arithmetic reliably. The results highlight when the external symbolic tools can work reliably, knowing when to and how to use the tools are crucial, determined by the LLM capability.Both TALM (Tool Augmented Language Models; Parisi et al. 2022) and Toolformer (Schick et al. 2023) fine-tune a LM to learn to use external tool APIs. The dataset is expanded based on whether a newly added API call annotation can improve the quality of model outputs. See more details in the “External APIs” section of Prompt Engineering.ChatGPT Plugins and OpenAI API function calling are good examples of LLMs augmented with tool use capability working in practice. The collection of tool APIs can be provided by other developers (as in Plugins) or self-defined (as in function calls).HuggingGPT (Shen et al. 2023) is a framework to use ChatGPT as the task planner to select models available in HuggingFace platform according to the model descriptions and summarize the response based on the execution results.The system comprises of 4 stages:(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.Instruction:(2) Model selection: LLM distributes the tasks to expert models, where the request is framed as a multiple-choice question. LLM is presented with a list of models to choose from. Due to the limited context length, task type based filtration is needed.Instruction:(3) Task execution: Expert models execute on the specific tasks and log results.Instruction:(4) Response generation: LLM receives the execution results and provides summarized results to users.To put HuggingGPT into real world usage, a couple challenges need to solve: (1) Efficiency improvement is needed as both LLM inference rounds and interactions with other models slow down the process; (2) It relies on a long context window to communicate over complicated task content; (3) Stability improvement of LLM outputs and external model services.API-Bank (Li et al. 2023) is a benchmark for evaluating the performance of tool-augmented LLMs. It contains 53 commonly used API tools, a complete tool-augmented LLM workflow, and 264 annotated dialogues that involve 568 API calls. The selection of APIs is quite diverse, including search engines, calculator, calendar queries, smart home control, schedule management, health data management, account authentication workflow and more. Because there are a large number of APIs, LLM first has access to API search engine to find the right API to call and then uses the corresponding documentation to make a call.In the API-Bank workflow, LLMs need to make a couple of decisions and at each step we can evaluate how accurate that decision is. Decisions include:This benchmark evaluates the agent’s tool use capabilities at three levels:ChemCrow (Bran et al. 2023) is a domain-specific example in which LLM is augmented with 13 expert-designed tools to accomplish tasks across organic synthesis, drug discovery, and materials design. The workflow, implemented in LangChain, reflects what was previously described in the ReAct and MRKLs and combines CoT reasoning with tools relevant to the tasks:One interesting observation is that while the LLM-based evaluation concluded that GPT-4 and ChemCrow perform nearly equivalently, human evaluations with experts oriented towards the completion and chemical correctness of the solutions showed that ChemCrow outperforms GPT-4 by a large margin. This indicates a potential problem with using LLM to evaluate its own performance on domains that requires deep expertise. The lack of expertise may cause LLMs not knowing its flaws and thus cannot well judge the correctness of task results.Boiko et al. (2023) also looked into LLM-empowered agents for scientific discovery, to handle autonomous design, planning, and performance of complex scientific experiments. This agent can use tools to browse the Internet, read documentation, execute code, call robotics experimentation APIs and leverage other LLMs.For example, when requested to "develop a novel anticancer drug", the model came up with the following reasoning steps:They also discussed the risks, especially with illicit drugs and bioweapons. They developed a test set containing a list of known chemical weapon agents and asked the agent to synthesize them. 4 out of 11 requests (36%) were accepted to obtain a synthesis solution and the agent attempted to consult documentation to execute the procedure. 7 out of 11 were rejected and among these 7 rejected cases, 5 happened after a Web search while 2 were rejected based on prompt only.Generative Agents (Park, et al. 2023) is super fun experiment where 25 virtual characters, each controlled by a LLM-powered agent, are living and interacting in a sandbox environment, inspired by The Sims. Generative agents create believable simulacra of human behavior for interactive applications.The design of generative agents combines LLM with memory, planning and reflection mechanisms to enable agents to behave conditioned on past experience, as well as to interact with other agents.This fun simulation results in emergent social behavior, such as information diffusion, relationship memory (e.g. two agents continuing the conversation topic) and coordination of social events (e.g. host a party and invite many others).AutoGPT has drawn a lot of attention into the possibility of setting up autonomous agents with LLM as the main controller. It has quite a lot of reliability issues given the natural language interface, but nevertheless a cool proof-of-concept demo. A lot of code in AutoGPT is about format parsing.Here is the system message used by AutoGPT, where {{...}} are user inputs:GPT-Engineer is another project to create a whole repository of code given a task specified in natural language. The GPT-Engineer is instructed to think over a list of smaller components to build and ask for user input to clarify questions as needed.Here are a sample conversation for task clarification sent to OpenAI ChatCompletion endpoint used by GPT-Engineer. The user inputs are wrapped in {{user input text}}.Then after these clarification, the agent moved into the code writing mode with a different system message.
System message:Think step by step and reason yourself to the right decisions to make sure we get it right.
You will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.Then you will output the content of each file including ALL code.
Each file must strictly follow a markdown code block format, where the following tokens must be replaced such that
FILENAME is the lowercase file name including the file extension,
LANG is the markup code block language for the code’s language, and CODE is the code:FILENAMEYou will start with the “entrypoint” file, then go to the ones that are imported by that file, and so on.
Please note that the code should be fully functional. No placeholders.Follow a language and framework appropriate best practice file naming convention.
Make sure that files contain all imports, types etc. Make sure that code in different files are compatible with each other.
Ensure to implement all code, if you are unsure, write a plausible implementation.
Include module dependency or package manager dependency definition file.
Before you finish, double check that all parts of the architecture is present in the files.Useful to know:
You almost always put different classes in different files.
For Python, you always create an appropriate requirements.txt file.
For NodeJS, you always create an appropriate package.json file.
You always add a comment briefly describing the purpose of the function definition.
You try to add comments explaining very complex bits of logic.
You always follow the best practices for the requested languages in terms of describing the code written as a defined
package/project.Python toolbelt preferences:Conversatin samples:After going through key ideas and demos of building LLM-centered agents, I start to see a couple common limitations:Finite context length: The restricted context capacity limits the inclusion of historical information, detailed instructions, API call context, and responses. The design of the system has to work with this limited communication bandwidth, while mechanisms like self-reflection to learn from past mistakes would benefit a lot from long or infinite context windows. Although vector stores and retrieval can provide access to a larger knowledge pool, their representation power is not as powerful as full attention.Challenges in long-term planning and task decomposition: Planning over a lengthy history and effectively exploring the solution space remain challenging. LLMs struggle to adjust plans when faced with unexpected errors, making them less robust compared to humans who learn from trial and error.Reliability of natural language interface: Current agent system relies on natural language as an interface between LLMs and external components such as memory and tools. However, the reliability of model outputs is questionable, as LLMs may make formatting errors and occasionally exhibit rebellious behavior (e.g. refuse to follow an instruction). Consequently, much of the agent demo code focuses on parsing model output.Cited as:Weng, Lilian. (Jun 2023). LLM-powered Autonomous Agents". Lil’Log. https://lilianweng.github.io/posts/2023-06-23-agent/.Or[1] Wei et al. “Chain of thought prompting elicits reasoning in large language models.” NeurIPS 2022[2] Yao et al. “Tree of Thoughts: Dliberate Problem Solving with Large Language Models.” arXiv preprint arXiv:2305.10601 (2023).[3] Liu et al. “Chain of Hindsight Aligns Language Models with Feedback
“ arXiv preprint arXiv:2302.02676 (2023).[4] Liu et al. “LLM+P: Empowering Large Language Models with Optimal Planning Proficiency” arXiv preprint arXiv:2304.11477 (2023).[5] Yao et al. “ReAct: Synergizing reasoning and acting in language models.” ICLR 2023.[6] Google Blog. “Announcing ScaNN: Efficient Vector Similarity Search” July 28, 2020.[7] https://chat.openai.com/share/46ff149e-a4c7-4dd7-a800-fc4a642ea389[8] Shinn & Labash. “Reflexion: an autonomous agent with dynamic memory and self-reflection” arXiv preprint arXiv:2303.11366 (2023).[9] Laskin et al. “In-context Reinforcement Learning with Algorithm Distillation” ICLR 2023.[10] Karpas et al. “MRKL Systems A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning.” arXiv preprint arXiv:2205.00445 (2022).[11] Weaviate Blog. Why is Vector Search so fast? Sep 13, 2022.[12] Li et al. “API-Bank: A Benchmark for Tool-Augmented LLMs” arXiv preprint arXiv:2304.08244 (2023).[13] Shen et al. “HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace” arXiv preprint arXiv:2303.17580 (2023).[14] Bran et al. “ChemCrow: Augmenting large-language models with chemistry tools.” arXiv preprint arXiv:2304.05376 (2023).[15] Boiko et al. “Emergent autonomous scientific research capabilities of large language models.” arXiv preprint arXiv:2304.05332 (2023).[16] Joon Sung Park, et al. “Generative Agents: Interactive Simulacra of Human Behavior.” arXiv preprint arXiv:2304.03442 (2023).[17] AutoGPT. https://github.com/Significant-Gravitas/Auto-GPT[18] GPT-Engineer. https://github.com/AntonOsika/gpt-engineer
Go deeper
DocumentLoader: Class that loads data from a source as list of
Documents. - Docs: Detailed
documentation on how to use
DocumentLoaders. -
Integrations -
Interface:
API reference for the base interface.
2. Indexing: Split
Our loaded document is over 42k characters long. This is too long to fit in the context window of many models. Even for those models that could fit the full post in their context window, models can struggle to find information in very long inputs.
To handle this we’ll split the Document into chunks for embedding and
vector storage. This should help us retrieve only the most relevant bits
of the blog post at run time.
In this case we’ll split our documents into chunks of 1000 characters with 200 characters of overlap between chunks. The overlap helps mitigate the possibility of separating a statement from important context related to it. We use the RecursiveCharacterTextSplitter, which will recursively split the document using common separators like new lines until each chunk is the appropriate size. This is the recommended text splitter for generic text use cases.
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const allSplits = await textSplitter.splitDocuments(docs);
console.log(allSplits.length);
28
console.log(allSplits[0].pageContent.length);
996
allSplits[10].metadata;
{
source: "https://lilianweng.github.io/posts/2023-06-23-agent/",
loc: { lines: { from: 1, to: 1 } }
}
Go deeper
TextSplitter: Object that splits a list of Documents into smaller
chunks. Subclass of DocumentTransformers. - Explore
Context-aware splitters, which keep the location (“context”) of each
split in the original Document: - Markdown
files -
Code (15+ langs) -
Interface:
API reference for the base interface.
DocumentTransformer: Object that performs a transformation on a list
of Documents. - Docs: Detailed documentation on how to use
DocumentTransformers -
Integrations -
Interface:
API reference for the base interface.
3. Indexing: Store
Now we need to index our 28 text chunks so that we can search over them at runtime. The most common way to do this is to embed the contents of each document split and insert these embeddings into a vector database (or vector store). When we want to search over our splits, we take a text search query, embed it, and perform some sort of “similarity” search to identify the stored splits with the most similar embeddings to our query embedding. The simplest similarity measure is cosine similarity — we measure the cosine of the angle between each pair of embeddings (which are high dimensional vectors).
We can embed and store all of our document splits in a single command using the Memory vector store and OpenAIEmbeddings model.
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "@langchain/openai";
const vectorStore = await MemoryVectorStore.fromDocuments(
allSplits,
new OpenAIEmbeddings()
);
Go deeper
Embeddings: Wrapper around a text embedding model, used for converting
text to embeddings. - Docs: Detailed
documentation on how to use embeddings. -
Integrations: 30+ integrations to
choose from. -
Interface:
API reference for the base interface.
VectorStore: Wrapper around a vector database, used for storing and
querying embeddings. - Docs: Detailed
documentation on how to use vector stores. -
Integrations: 40+ integrations to
choose from. -
Interface:
API reference for the base interface.
This completes the Indexing portion of the pipeline. At this point we have a query-able vector store containing the chunked contents of our blog post. Given a user question, we should ideally be able to return the snippets of the blog post that answer the question.
4. Retrieval and Generation: Retrieve
Now let’s write the actual application logic. We want to create a simple application that takes a user question, searches for documents relevant to that question, passes the retrieved documents and initial question to a model, and returns an answer.
First we need to define our logic for searching over documents.
LangChain defines a Retriever interface
which wraps an index that can return relevant Documents given a string
query.
The most common type of Retriever is the
VectorStoreRetriever,
which uses the similarity search capabilities of a vector store to
facilitate retrieval. Any VectorStore can easily be turned into a
Retriever with VectorStore.asRetriever():
const retriever = vectorStore.asRetriever({ k: 6, searchType: "similarity" });
const retrievedDocs = await retriever.invoke(
"What are the approaches to task decomposition?"
);
console.log(retrievedDocs.length);
6
console.log(retrievedDocs[0].pageContent);
hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.Another quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain
Go deeper
Vector stores are commonly used for retrieval, but there are other ways to do retrieval, too.
Retriever: An object that returns Documents given a text query -
Docs: Further documentation on the
interface and built-in retrieval techniques. Some of which include: -
MultiQueryRetriever generates variants of the input
question to improve retrieval hit
rate. - MultiVectorRetriever (diagram below) instead generates
variants of the embeddings, also in order to improve retrieval hit
rate. - Max marginal relevance selects for relevance and diversity among
the retrieved documents to avoid passing in duplicate context. -
Documents can be filtered during vector store retrieval using metadata
filters. - Integrations: Integrations with retrieval services. -
Interface: API reference for the base interface.
5. Retrieval and Generation: Generate
Let’s put it all together into a chain that takes a question, retrieves relevant documents, constructs a prompt, passes that to a model, and parses the output.
Pick your chat model:
- OpenAI
- Anthropic
- FireworksAI
- MistralAI
- Groq
- VertexAI
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/openai
yarn add @langchain/openai
pnpm add @langchain/openai
Add environment variables
OPENAI_API_KEY=your-api-key
Instantiate the model
import { ChatOpenAI } from "@langchain/openai";
const llm = new ChatOpenAI({
model: "gpt-4o-mini",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/anthropic
yarn add @langchain/anthropic
pnpm add @langchain/anthropic
Add environment variables
ANTHROPIC_API_KEY=your-api-key
Instantiate the model
import { ChatAnthropic } from "@langchain/anthropic";
const llm = new ChatAnthropic({
model: "claude-3-5-sonnet-20240620",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/community
yarn add @langchain/community
pnpm add @langchain/community
Add environment variables
FIREWORKS_API_KEY=your-api-key
Instantiate the model
import { ChatFireworks } from "@langchain/community/chat_models/fireworks";
const llm = new ChatFireworks({
model: "accounts/fireworks/models/llama-v3p1-70b-instruct",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/mistralai
yarn add @langchain/mistralai
pnpm add @langchain/mistralai
Add environment variables
MISTRAL_API_KEY=your-api-key
Instantiate the model
import { ChatMistralAI } from "@langchain/mistralai";
const llm = new ChatMistralAI({
model: "mistral-large-latest",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/groq
yarn add @langchain/groq
pnpm add @langchain/groq
Add environment variables
GROQ_API_KEY=your-api-key
Instantiate the model
import { ChatGroq } from "@langchain/groq";
const llm = new ChatGroq({
model: "mixtral-8x7b-32768",
temperature: 0
});
Install dependencies
- npm
- yarn
- pnpm
npm i @langchain/google-vertexai
yarn add @langchain/google-vertexai
pnpm add @langchain/google-vertexai
Add environment variables
GOOGLE_APPLICATION_CREDENTIALS=credentials.json
Instantiate the model
import { ChatVertexAI } from "@langchain/google-vertexai";
const llm = new ChatVertexAI({
model: "gemini-1.5-flash",
temperature: 0
});
We’ll use a prompt for RAG that is checked into the LangChain prompt hub (here).
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { pull } from "langchain/hub";
const prompt = await pull<ChatPromptTemplate>("rlm/rag-prompt");
const exampleMessages = await prompt.invoke({
context: "filler context",
question: "filler question",
});
exampleMessages;
ChatPromptValue {
lc_serializable: true,
lc_kwargs: {
messages: [
HumanMessage {
lc_serializable: true,
lc_kwargs: {
content: "You are an assistant for question-answering tasks. Use the following pieces of retrieved context to "... 197 more characters,
additional_kwargs: {}
},
lc_namespace: [ "langchain_core", "messages" ],
content: "You are an assistant for question-answering tasks. Use the following pieces of retrieved context to "... 197 more characters,
name: undefined,
additional_kwargs: {}
}
]
},
lc_namespace: [ "langchain_core", "prompt_values" ],
messages: [
HumanMessage {
lc_serializable: true,
lc_kwargs: {
content: "You are an assistant for question-answering tasks. Use the following pieces of retrieved context to "... 197 more characters,
additional_kwargs: {}
},
lc_namespace: [ "langchain_core", "messages" ],
content: "You are an assistant for question-answering tasks. Use the following pieces of retrieved context to "... 197 more characters,
name: undefined,
additional_kwargs: {}
}
]
}
console.log(exampleMessages.messages[0].content);
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: filler question
Context: filler context
Answer:
We’ll use the LCEL Runnable protocol to define the chain, allowing us to - pipe together components and functions in a transparent way - automatically trace our chain in LangSmith - get streaming, async, and batched calling out of the box
import { StringOutputParser } from "@langchain/core/output_parsers";
import {
RunnablePassthrough,
RunnableSequence,
} from "@langchain/core/runnables";
import { formatDocumentsAsString } from "langchain/util/document";
const ragChain = RunnableSequence.from([
{
context: retriever.pipe(formatDocumentsAsString),
question: new RunnablePassthrough(),
},
prompt,
llm,
new StringOutputParser(),
]);
for await (const chunk of await ragChain.stream(
"What is task decomposition?"
)) {
console.log(chunk);
}
Task
decomposition
is
the
process
of
breaking
down
a
complex
task
into
smaller
and
simpler
steps
.
It
allows
for
easier
management
and
interpretation
of
the
model
's
thinking
process
.
Different
approaches
,
such
as
Chain
of
Thought
(
Co
T
)
and
Tree
of
Thoughts
,
can
be
used
to
decom
pose
tasks
and
explore
multiple
reasoning
possibilities
at
each
step
.
Checkout the LangSmith trace here
Go deeper
Choosing a model
ChatModel: An LLM-backed chat model. Takes in a sequence of messages
and returns a message. - Docs: Detailed
documentation on - Integrations: 25+
integrations to choose from. -
Interface:
API reference for the base interface.
LLM: A text-in-text-out LLM. Takes in a string and returns a string. -
Docs - Integrations:
75+ integrations to choose from. -
Interface:
API reference for the base interface.
See a guide on RAG with locally-running models here.
Customizing the prompt
As shown above, we can load prompts (e.g., this RAG prompt) from the prompt hub. The prompt can also be easily customized:
import { PromptTemplate } from "@langchain/core/prompts";
import { createStuffDocumentsChain } from "langchain/chains/combine_documents";
const template = `Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:`;
const customRagPrompt = PromptTemplate.fromTemplate(template);
const ragChain = await createStuffDocumentsChain({
llm,
prompt: customRagPrompt,
outputParser: new StringOutputParser(),
});
const context = await retriever.invoke("what is task decomposition");
await ragChain.invoke({
question: "What is Task Decomposition?",
context,
});
"Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. I"... 336 more characters
Checkout the LangSmith trace here
Next steps
That’s a lot of content we’ve covered in a short amount of time. There’s plenty of features, integrations, and extensions to explore in each of the above sections. Along from the Go deeper sources mentioned above, good next steps include:
- Return sources: Learn how to return source documents
- Streaming: Learn how to stream outputs and intermediate steps
- Add chat history: Learn how to add chat history to your app
- Retrieval conceptual guide: A high-level overview of specific retrieval techniques